uXOM: Efficient eXecute-Only Memory on Cortex-M论文笔记
作者:Donghyun Kwon, Jangseop Shin, Giyeol Kim, Byoungyoung Lee, Yeongpil Cho, Yunheung Paek@ECE, Seoul National University, ISRC, Seoul National University Computer Science, Purdue University, School of Software, Soongsil University
链接:https://www.usenix.org/conference/usenixsecurity19/presentation/kwon
作者们主要设计了一种能在低端设备上软件实现的只执行内存管理,可以避免由于可读甚至可写所带来的非法$pc、代码重用攻击等等。
XOM:Execute Only Memory
uXOM:XOM optimization in Cortex-M
XOM实际上已经在诸如X86、AArch64等高端CPU上得到了应用,但是在低端上的应用仍十分缺乏,而且由于当下物联网的推广,这种硬件升级的方式实际上很难应用到大量的物联设备上。因此作者设计的是软件层面的XOM。
选择Cortex-M:因为对于大多数低端设备,其原本并不支持XOM技术,而在这些低端设备中由Cortex-M构成的设备占了非常大的比重,因此作者希望能借用Cortex-M已有的架构和技术,从软件层面上来实现XOM,被作者称为uXOM
最后的评估,uXOM相比于另一个对Cortex-M的XOM软件实现在执行时间、代码大小和能量消耗上都更优
Introduction
在当下的基本权限设置环境下(RWX、RW、RX、RO、NA),即便攻击者无法修改或注入代码,由于代码中可能含有密钥或知识产权的内容,系统仍可能收到来自攻击者读取代码的威胁。最重要的是在攻击者得知了某地址上的代码内容后,系统无法抵御代码重用的攻击。因此应用XOM技术可以抵御这类攻击。
一种简单的实现是对执行段加密,执行时再恢复,但包括该方法在内的大多数的软件XOM手段都存在效率低下的问题,因此当前高端处理器上都在原有的内存权限模型上增加了一个XO,但这对于很多低端处理器并不适用,因此软件实现XOM仍然非常需要。
当前的纯软件实现主要有软件故障隔离技术SFI,但其在某些处理器(尤其是Cortex-M)上性能较差,甚至在默写情况下可bypass。因此作者设计了uXOM,利用了ARM上特殊的unprilileged load/store指令,该指令和CPU当前的特权级别无关。
另一方面,考虑到环境切换的效率问题,当前很多微型嵌入式设备中的内核和用户程序都是以特权模式运行的。uXOM则是将所有的内存指令都替换为了非特权指令,并将代码段设置为特权。则代码无论如何都无法访问代码段的内容,但CPU的执行仍然是特权的,因此仍可以正常执行代码,间接地实现了XOM。但对于一些特殊的指令,如访问外设映射的内存、以及独占/原子访问内存的指令都是必须在特权下才能进行的,因此对这类指令应保留原样。
但上述的特例也会带来问题:攻击者可以利用这些指令来关闭MPU或直接读取代码关键信息。因此对每条这类指令都还需要额外的验证代码来检测每次调用这类指令时不会破坏uXOM的保护。同时,这些额外代码必须是原子的,内存指令和验证代码必须都原子地执行,因此作者还设计了原子验证模型。
另一个挑战是,攻击者可能还利用未对齐的Thumb指令或嵌在代码段未被执行的数据来进行代码重用攻击。因此uXOM还需要找到这些有潜在危险的指令并将其替换为等效但不包含上述指令的指令序列
Background
ARMv7-M并不支持内存虚拟化,内存map如下:
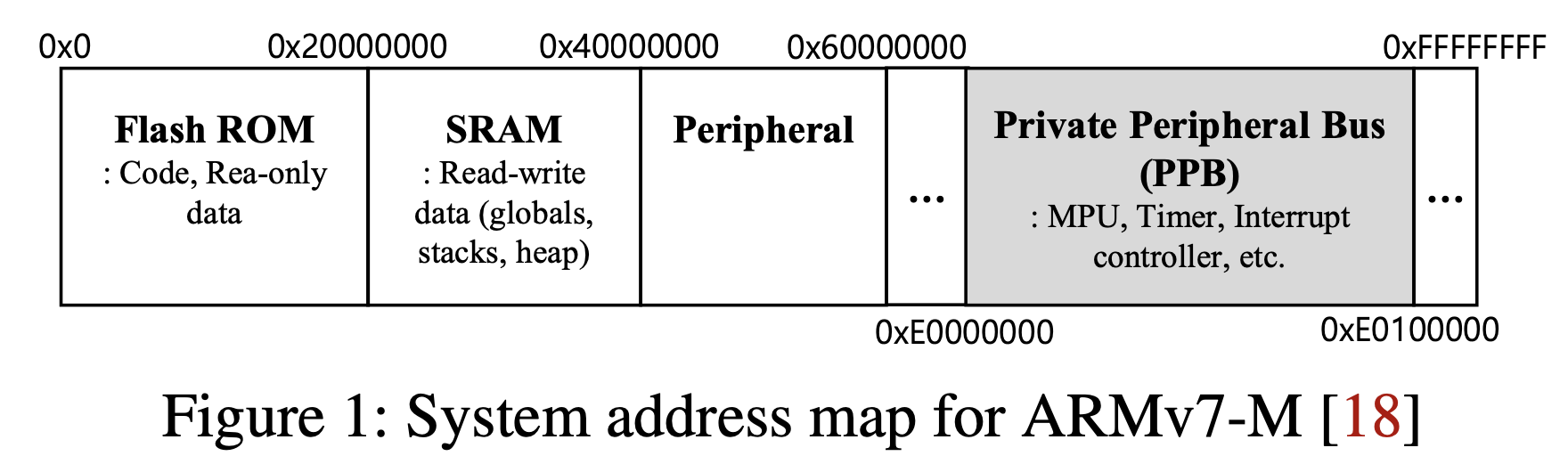
Peripheral:GPIO、UART等外设
ARMv7-M architecture
- Used in Cortex-M3/4/7 processors
- prominent processor in embedded systems
- No MMU
- No execute-only permission in MPU (Memory Protection Unit)
- Available permissions: NA, RO, RX, RW, RWX
因此是无法仅通过MPU设置来开启XOM保护的
LDRT/STRT强制非特权指令
ARMv7-M的硬件机制中断上下文切换以及当PC值变成EXC_RETURN时会发生中断返回
还有一个特性是:ARMv7-M实际上有两个sp:main sp和process sp,异常中只能使用main sp但非异常代码可选择两个中的一个,具体用哪个由内部的CONTROl寄存器决定,因此两个sp始终只显示为一个
Threat Model and Assumption
在作者的攻击环境中,攻击具有如下条件:
- 攻击者仅针对目标固件发起软件层面的攻击,拥有如任意地址读写的权限,并能够控制pc,能触发异常处理甚至是异常处理中的漏洞
- 不考虑对固件离线的攻击(如拆卸、操纵或替换固件),因为这些往往可通过固件加密/签名来保护
- 不考虑硬件层面的攻击(如bus总线探测,物理内存篡改等等)
相应的,作者也提出了相应的假定条件:
- 作者认为包括异常处理程序,固件的所有部分都应该是不可信的
- 所有的指令都在特权模式下运行
- 处理器支持MPU和非特权指令
Challenges & Design
理想情况下,uXOM可将所有内存指令转换为非特权指令。然后,它将在系统引导时配置MPU,以将代码区域设置为RX(用于特权访问)和NA(非特权)。它还将特权访问和非特权访问的其他存储区域(即数据区域)设置为不可执行。配置完成后,uXOM以特权身份执行代码。允许所有转换后的内存指令(即非特权内存指令)以与以前相同的方式访问数据区域。但是,禁止这些指令访问MPU和VTOR所在的代码区域和PPB区域,这对于uXOM的安全至关重要。
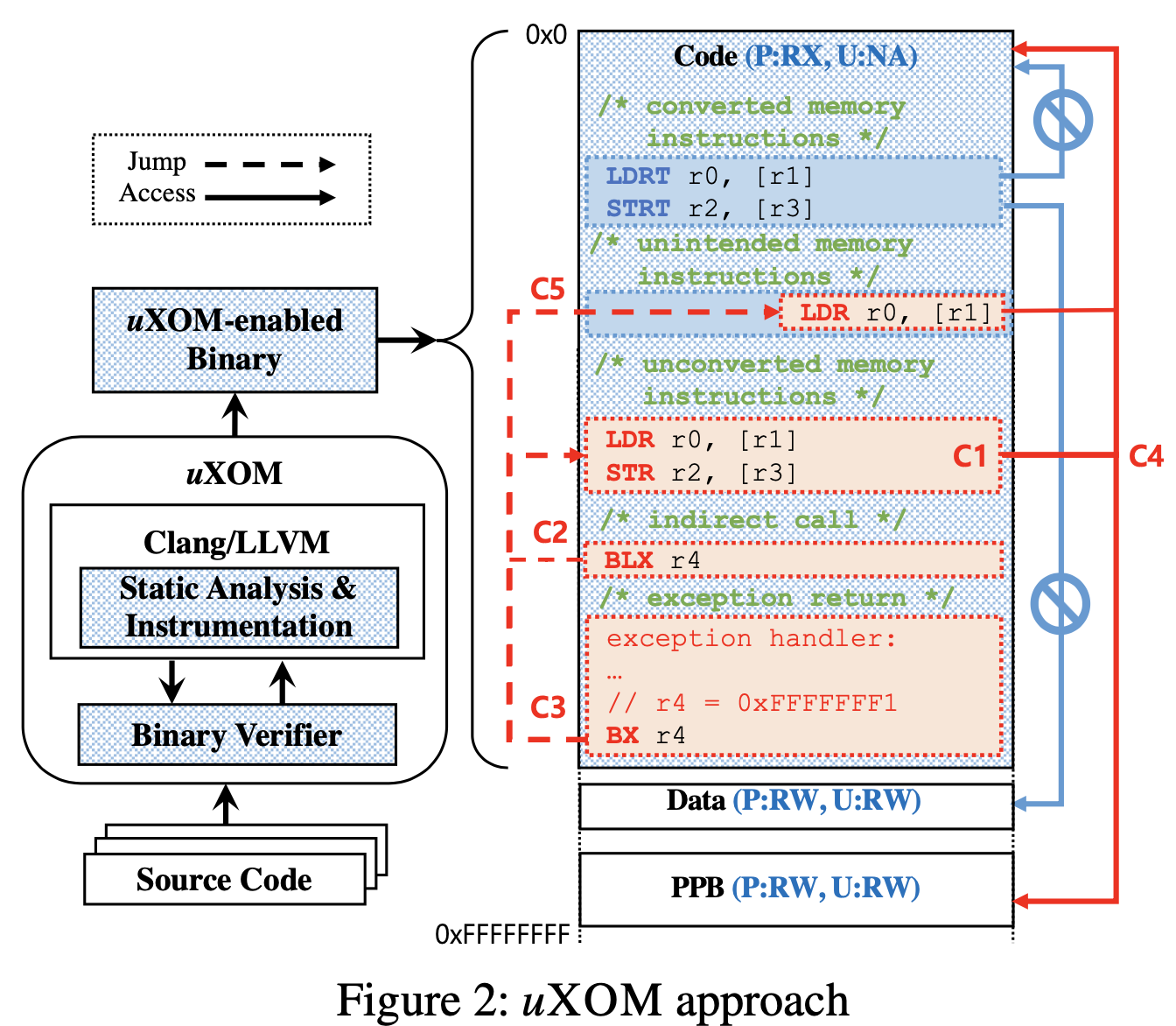
最终,uXOM实现为一个LLVM的pass以及一个二进制的验证器,也就是从源代码编译开始得到一个添加uXOM保护的binary,并在执行时保证权限控制。基础设计包括如下两部分:
-
指令替换:
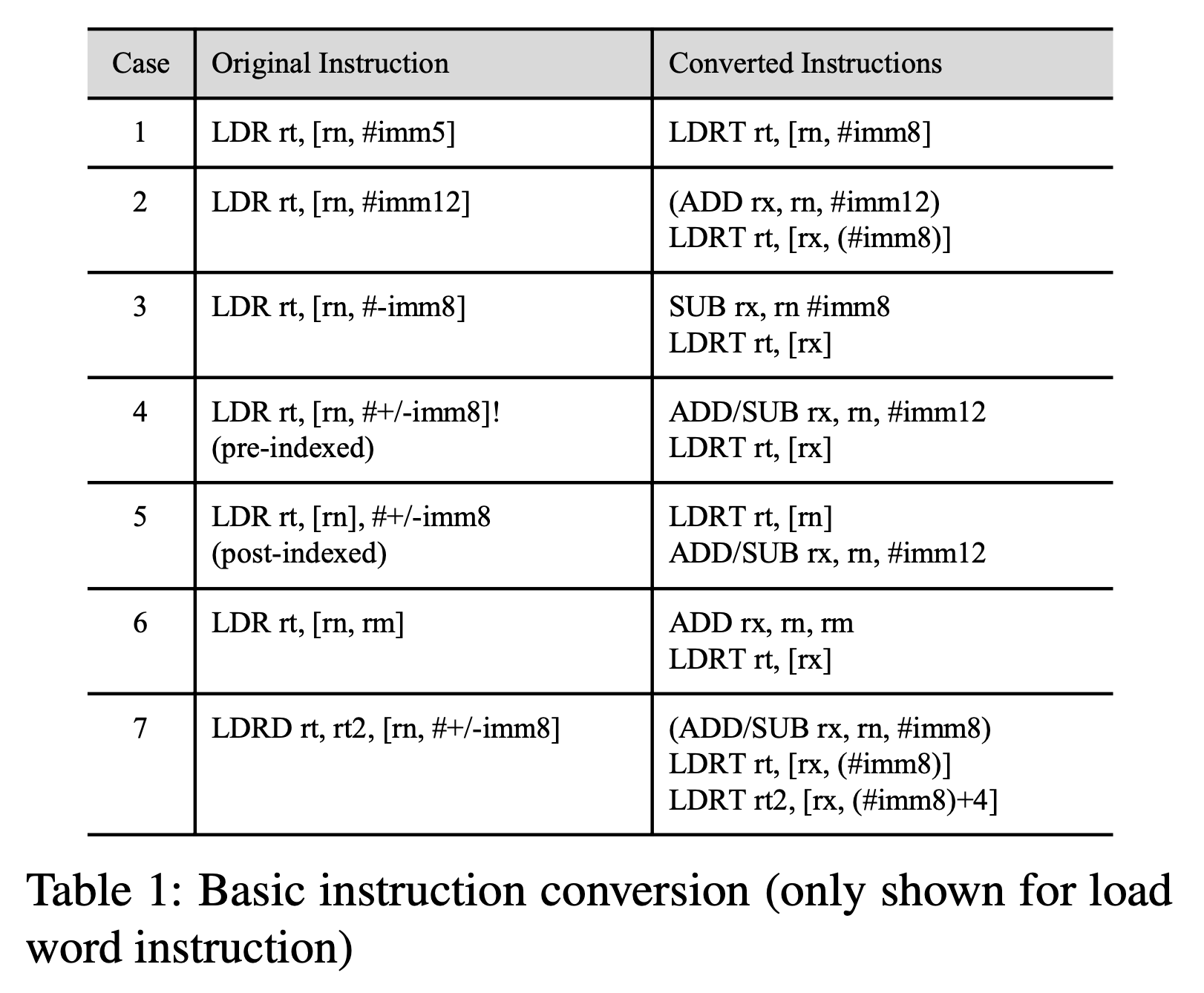
-
权限控制:
对每个段的具体权限分配需要uXOM在编译时确定各个段的用途,地址范围,从而在reset handler的前期就进行好MPU的设置,从而在攻击发生之前设置好程序运行时整个内存空间的(un)previlege权限分配
在以上理想设计基础上,需要面临如下一些挑战:
-
一些没法转换成其他指令的指令:
如:LDREX, STREX这类原子指令、以及对外设总线的映射内存访问的指令等等,这些都必须在特权模式下进行
-
恶意的间接跳转:
攻击者可以故意跳到上述的这些无法转换的指令地址上执行load/store,甚至修改MPU导致uXOM失效
-
恶意的异常处理返回: 异常处理的上下文保存在堆栈上,攻击者可利用异常处理中的漏洞修改上下文,并可以通过给pc分配EXC_RETURN来直接触发中断返回
-
恶意数据操纵:
由于具有任意地址读写,攻击者可能可以通过构造恶意数据来利用未转化的load/store,如控制参数来调用MPU配置函数等
-
非法指令:
如:thumb指令或执行了在代码段中嵌入的数据
针对这些问题,相应的解决方案有:
-
寻找无法转化的指令:
对于涉及到原子访问的指令,使用disassembler找特定的opcode来定位
对于涉及到外设总线访问的指令,检查访问的地址是否真正属于PPB的范围,经验中大部分对PPB的访问都是PPB的基址偏移的间接访问,对于极少数特殊情况再手动标注识别
-
添加原子操作验证:
在原子操作前添加验证代码,并保证验证代码和目标指令之间是原子执行的,以确保攻击者在没有适当验证的情况下无法执行未转换的加载/存储。
verification routine的具体设计如下:

对于验证代码,有如下设计:
- 使用专门一个寄存器作为这些无法转换的指令的访问地址的基址寄存器
- 如果一个原子操作序列正在被执行,那么这个专用寄存器就存着敏感数据地址
- 否则,这个寄存器存着一个不会对uXOM功能带来影响的值
- 这个寄存器只能被用在原子操作代码的验证阶段
由于增加了寄存器之间的切换,因此带来了较大的overhead
同时,在验证代码前关闭中断,在原子操作后打开中断,防止攻击者在验证代码后通过产生异常来bypass检查
进一步的,使用SP寄存器作为这个专用寄存器,因为其正常情况下肯定指向堆栈这类可读写不可执行的段的性质,来降低开销,最终的实现如下:

为了保证SP在检查代码外的任何地方都保持稳定指向安全区域不被攻击者修改后利用,uXOM还需要在sp修改时也添加检查,分为三类:
- sp被非常数(即寄存器)修改:如alloca函数、分配可变大小栈上数组等,这种情况很少,因此每个地方都插入sp检查代码
- sp被修改后立马抛出中断来避免检查:因此需要在中断入口处也添加sp检查
- sp常数加减:常见于函数末尾或开头,攻击者可以叠加多条来控制sp,当前已有的内存Redzone可以一定程度抵御这种攻击,对Redzone无法抵御的作者也会添加sp检查
-
对于一些非法指令如:
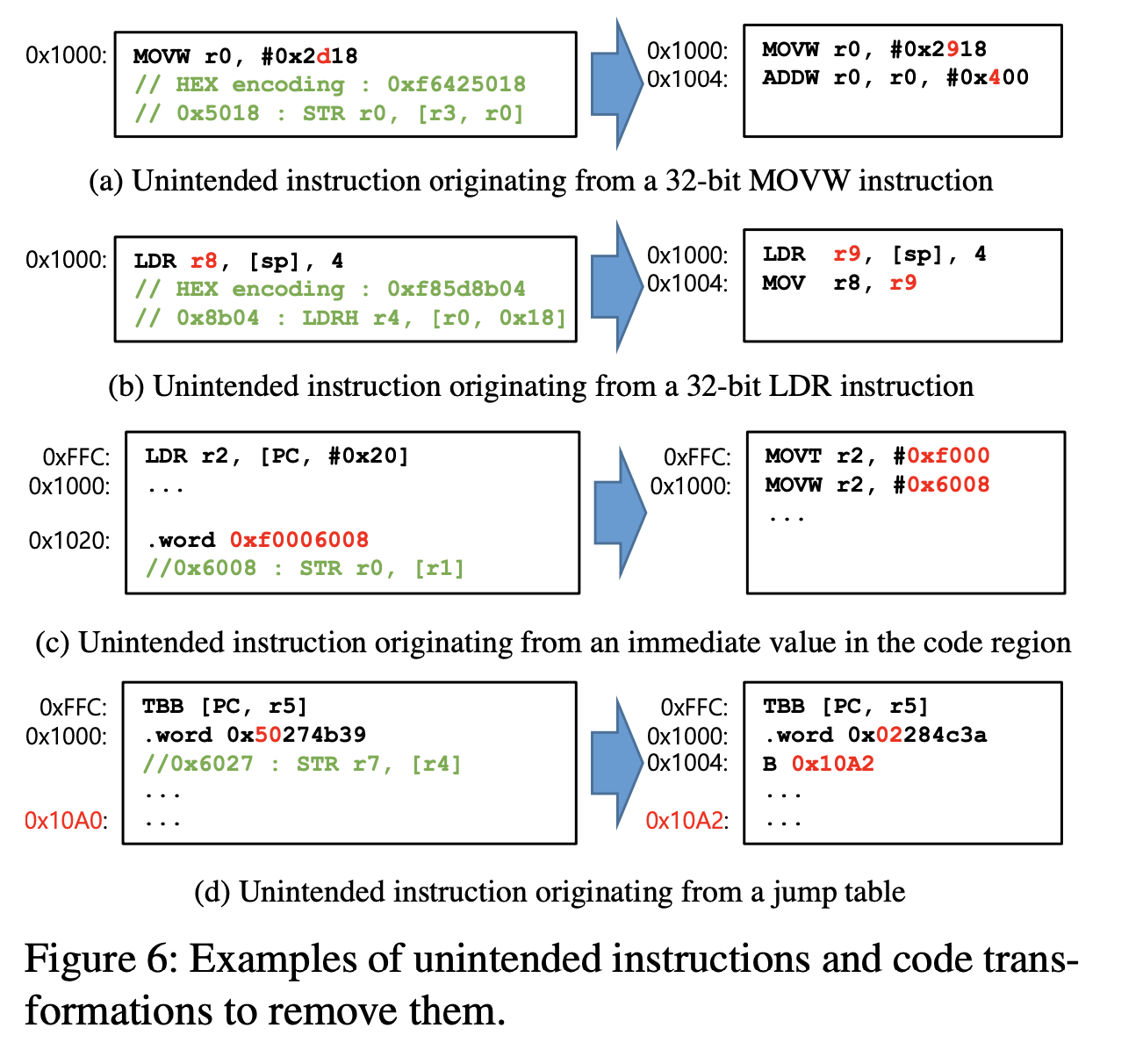 有如下方法:
有如下方法:- 使用静态分析的方法找到所有的这些可能被利用的非法指令
- 将这些可能被利用的指令定位,重新编译程序,替换成相同功能的安全指令序列
- 重新扫描,如还存在则执行步骤1
Optimization
对基于pc偏移的load/store不转化
对基于sp偏移的load/store不转化
Evaluation
实验环境
LLVM 5.0用来code instrumentation
R2用来静态分析
Arduino-due:使用Cortex-M处理器
RIOT-OS & BEEBS benchmark suite
主要是和SFI实现的XOM比较,并为SFI在Cortex-M上使用对SFI进行了一些修改
Runtime Overhead
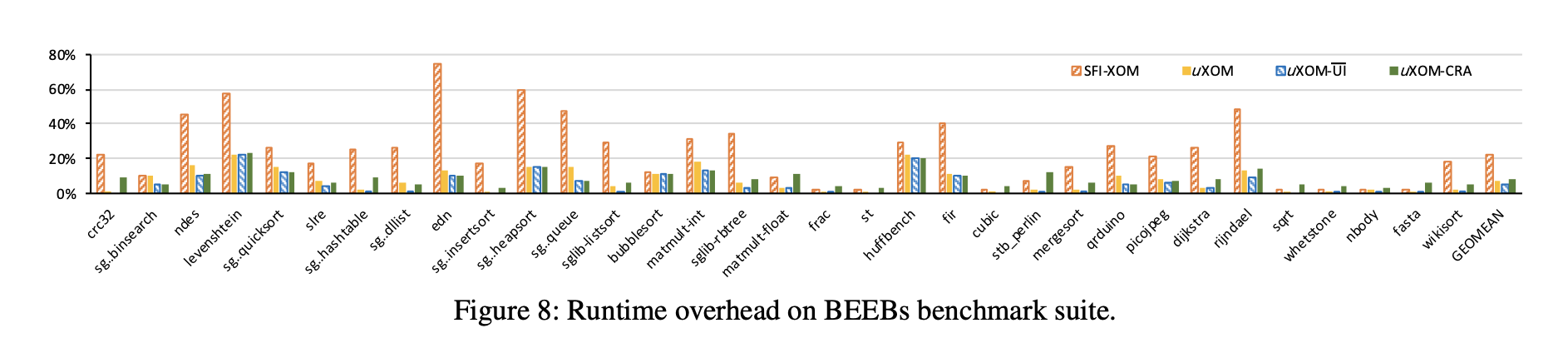
由于低端处理器的小缓存甚至无缓存导致了SFI性能有较大下降。导致对于uXOM,所有基准的几何平均开销为7.3%,对于基于SFI的XOM,则为22.7%。对于Huffbench基准,uXOM的最坏情况开销为22.3%,对于edn基准,基于SFI的XOM的最坏情况开销为75.1%。
同时还收集了开销的break down:
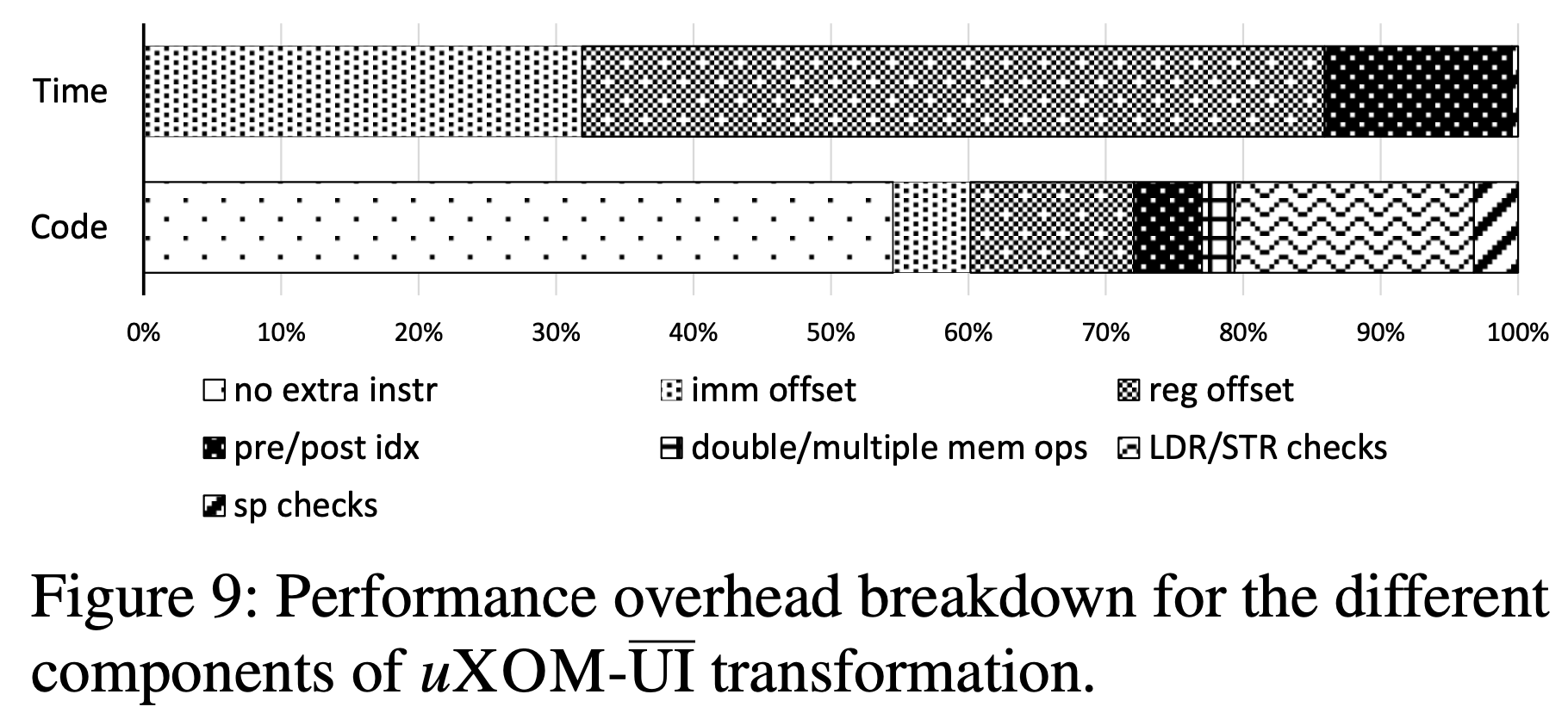
这告诉我们,大多数加载/存储指令都使用立即偏移量寻址模式,并且偏移量通常很小,因此适合无特权指令的立即数字段。如我们所见,以这种方式转换的指令虽然占大多数,但不会增加运行时的开销。即使无特权指令的长度为32位,除非插入其他指令,否则它们不会增加开销。这是uXOM的一大优势,这也是uXOM可以比基于SFI的XOM高效得多的主要原因。
插入用于堆栈修改的sp检查对性能的影响可以忽略不计,因为我们的分析发现,只有少于30%的基于sp的内存指令才需要sp检查。
占大多数开销的指令转换类型是寄存器-寄存器寻址模式(寄存器偏移量)的一种。尽管它们仅占所有转换的8.6%,但它们占uXOM-UI总开销的54%。原因是它们经常在耗时的循环中使用,例如索引数组变量。
CodeSize & Energy Overhead
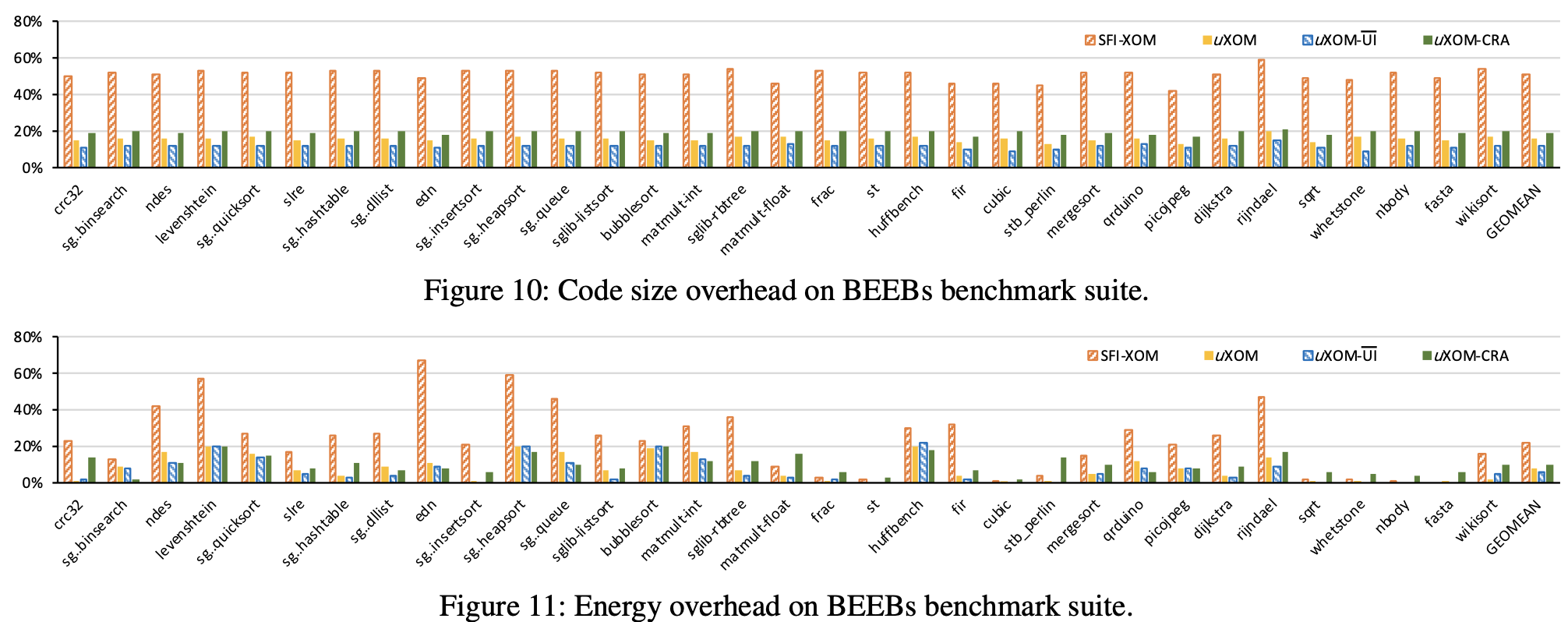
Codesize:为了查看uXOM插入指令的影响,我们测量了最终二进制文件中代码的大小,不包括数据大小。图10显示了基于uXOM和基于SFI的XOM的结果。对于uXOM,代码大小增加了15.7%,而对于基于SFI的XOM,代码大小增加了50.8%。它表明,与基于SFI的XOM相比,uXOM可以用更少的代码大小开销实现XOM。另外,我们测量到uXOM-UI的几何平均开销为11.6%,这表明用于删除意外指令的增加代码量为4.1%。
Energy:对于uXOM,所有基准的几何平均值为7.5%,略大于uXOM-UI的5.8%,但远低于基于SFI的XOM的22.3%。 由于能量也受执行时间的影响,因此结果与执行时间具有相似的趋势。
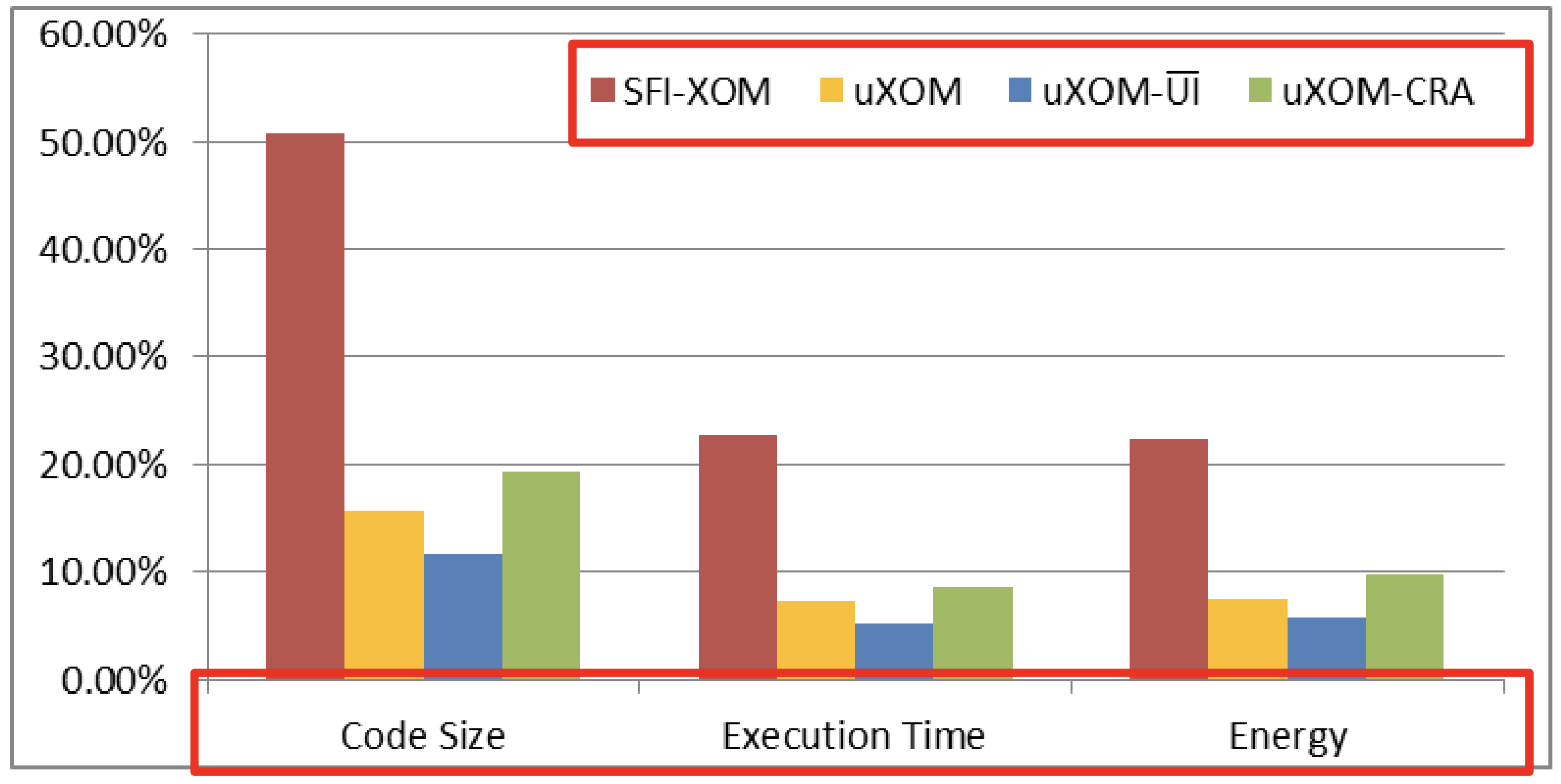
有关CRA:基于Readactor 添加了对函数指针的保护,先跳到B指令再跳到真正函数,返回时再先跳到B指令再跳到原来位置。展示了我们CRA防御的实验结果以及uXOM,uXOM-UI和基于SFI的XOM的结果。它强加了8.6%的平均运行时开销,19.3%的代码大小开销和9.7%的能量开销。运行时开销仅比原始Readactor实现的开销略大(6.4%),这表明uXOM技术在低端嵌入式设备中的适用性。
Conclusion
- 本文使用软件层面的方式在Cortex-M处理器上实现MPU环境下的XOM
- 给了一个很广泛的攻击模型,即攻击者可以任意地址读写、可以控PC,同时系统也不需要开任何相关保护
- 在性能和安全性上都优于基于SFI的XOM实现
- uXOM也和现有的基于XOM的解决方案兼容