Matryoshka: fuzzing deeply nested branches论文笔记
作者:Peng Chen, Jianzhong Liu and Hao Chen@ByteDance AI Lab, ShanghaiTech University, University of California, Davis
链接:https://arxiv.org/pdf/1905.12228.pdf
本文主要想解决在fuzzing过程中很难找到如何进入到有大量条件语句嵌套的目标语句的路径约束的问题。
与AFL、QSYM和Angora相比有更独特的crash发现,作者将其分类为了41个新类别,并获得了12个CVE。
通过评估还发现了Matryoshka能有如此性能的关键原因:它仅收集了可能导致目标语句无法到达的约束嵌套,从而缩减了求解量
Intro
fuzzing灰盒测试(如AFL):对程序进行检测,以报告当前输入在运行时是否已探索新状态。如果当前输入触发了新的程序状态,则模糊器会将当前输入保留为进一步突变的种子。
灰盒测试优先考虑分支探索以有效触发难以到达的分支中的错误。与符号执行相比,灰盒测试避免了昂贵的符号约束求解,因此可以处理大型,复杂的程序。
fuzzing的程序状态指导突变(如Vuzzer, Steelix, QSYM和Angora):使用污点来追踪输入的哪些字节进入到了目标语句的外围条件判断中,针对这些字节突变来提高效率并使用梯度下降法来寻求分支约束的解决方案。
条件嵌套带来的问题到底出在哪?
对条件语句,要满足需要如下条件:
- 条件语句本身可到达
- 条件语句的条件满足
因此在嵌套的条件当中,设到条件语句的条件组为P,则对输入产生突变以满足当前条件s时很有可能破坏了先觉条件P,从而使s又无法访问了。
这个问题,由于之前的fuzzer无法追踪控制流,也无法追踪各个条件之间的污点流的约束,一直没能得到很好的解决。
这个问题在一些音频流处理程序中非常常见,而这些程序的漏洞也非常多,以下为一个常见的code snippet:

一般fuzzer在对6行的判断突变时往往会导致crc check不过,因此这些突变严重拖慢了效率。
作者使用Angora测试13个开源程序也验证了该观点,这些程序读取结构化输入,因此可能有许多嵌套的条件语句,深度嵌套的条件语句往往导致fuzzer很难深入到语句内部中去:
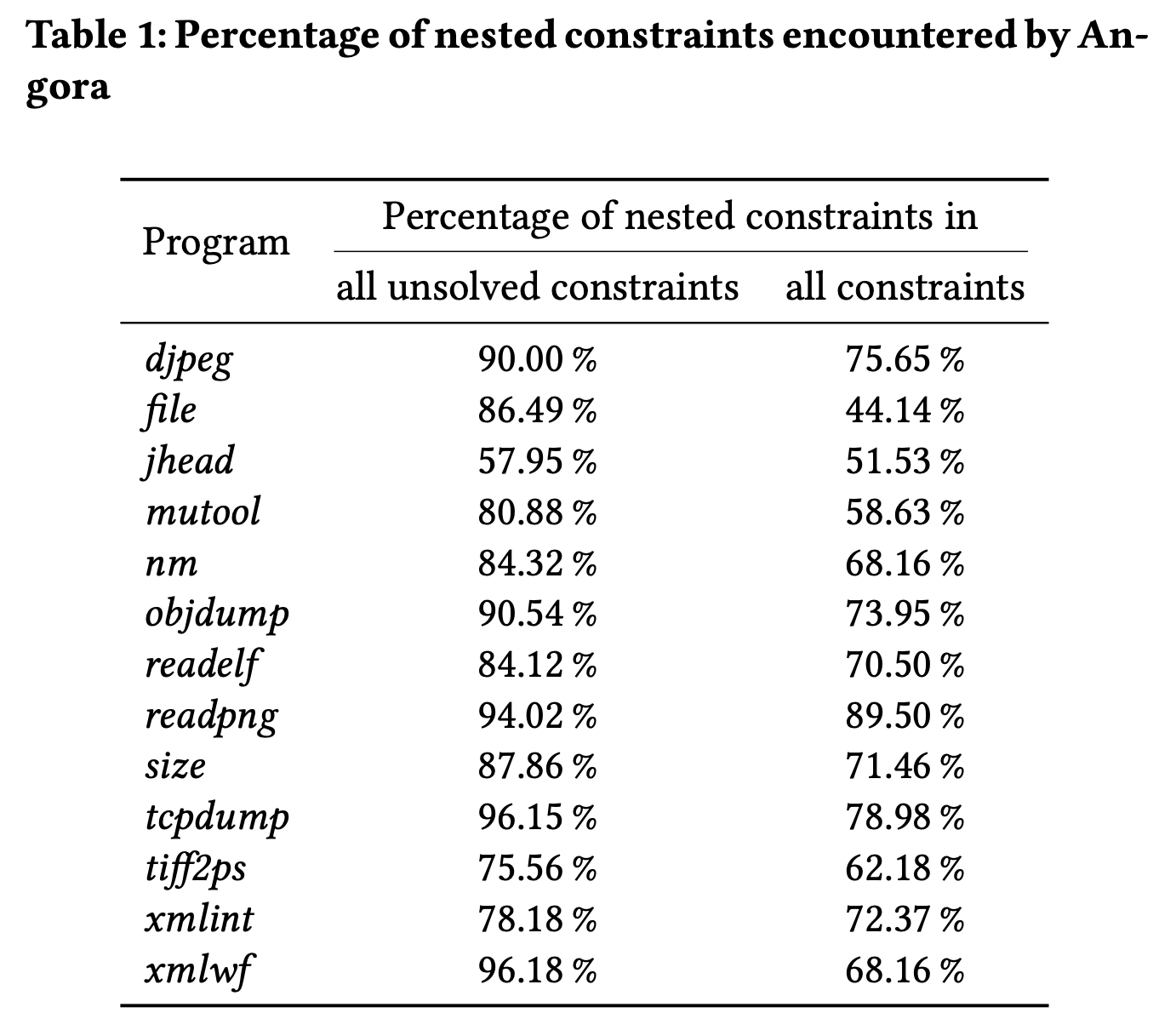
表中显示,大多数未解决的约束是嵌套的,范围从57.95%到接近100%。它还表明,嵌套约束占所有约束的很大一部分,范围从44.14%到89.50%。这些结果表明,解决嵌套约束可以显着提高灰盒模糊器的覆盖范围。
Problem to solve
示例:有如下代码片段:

假设当前的输入已经能够满足执行到line 6的false分支,现在想产生执行true分支的输入,步骤如下:
-
找到可能导致line 6无法执行到的条件语句:line 2,3,4
-
确定条件语句间的依赖关系,找到突变可能真正影响line 6执行的条件语句:line 2,3
-
解决找到的约束,来同时满足line 2,3,6的y输入突变
解决约束,作者又提出了3中方案:
- 保守突变:即不改变当前输入中和line 2,3(即line 6依赖的)相关的任何输入的任何字节
- 中立突变:对line6的输入进行突变时强制保留依赖行的分支情况,当产生符合要求的line 6输入时再回过头来验证依赖行能否满足分支情况不变。如不变则找到了满足的输入,否则若都不满足,则回溯依赖栈并继续尝试该策略
- 联合突变:将依赖栈上的所有依赖条件联合起来求解
而实际上,Matryoshka真正的效率提升是在寻找依赖条件集合上。传统的符号执行会收集条件嵌套中的所有条件,但该作者的工具仅在控制了目标语句的条件语句和和目标语句判断条件有污点依赖性的条件语句当中收集条件,这些条件往往只占了路径上所有条件中的很小一部分,从而优化了计算量。
下图显示了Matryoshka的设计:
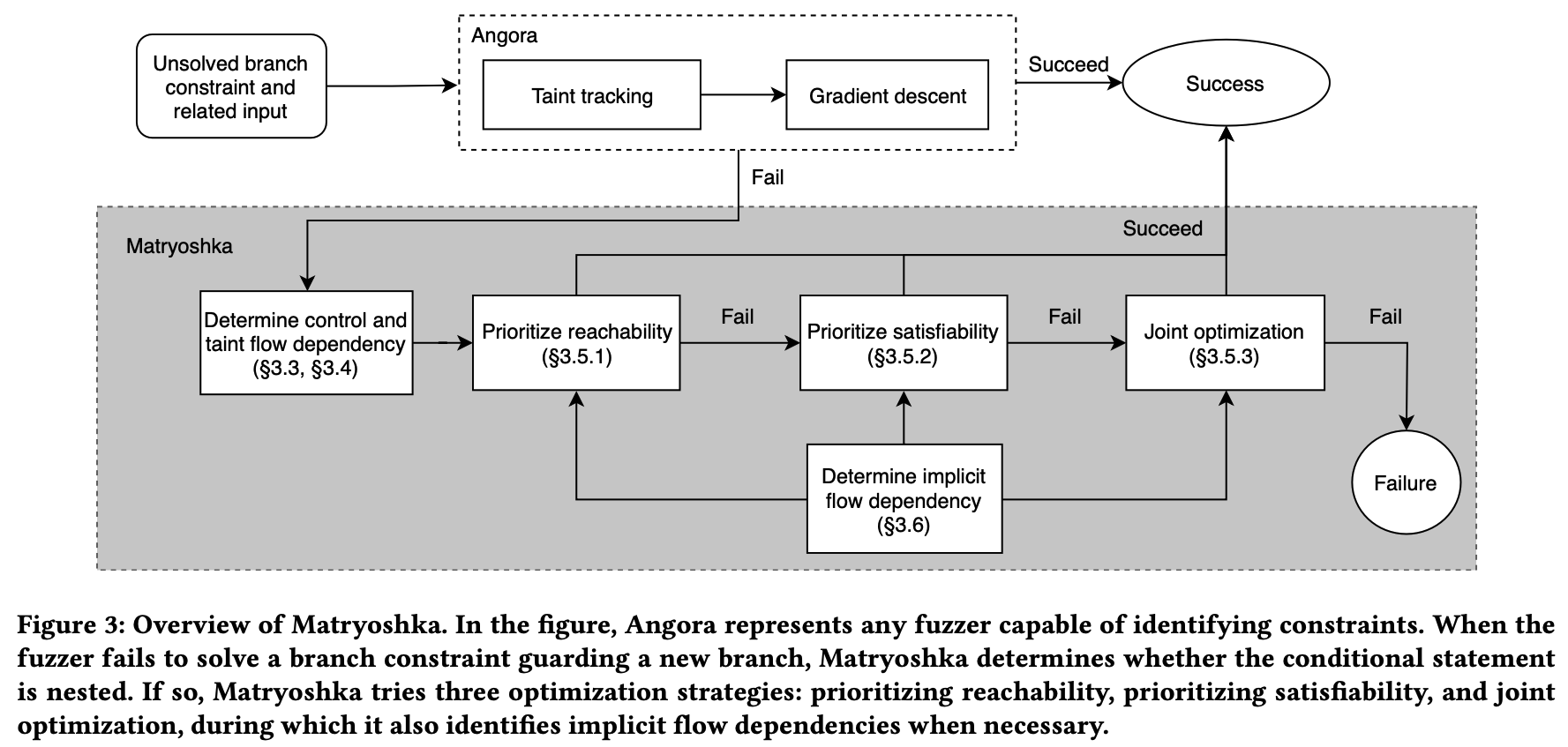
程序首先是执行了另一个fuzzer Angora的功能,当找到其难以找到特定路径输入的嵌套条件语句时交由Matryoshka执行。Matryoshka执行如下步骤:
-
在该条件语句的条件栈中判断该条件语句的最近前向控制条件语句集合,分为函数内(Intraprocedural)的和函数外(Interprocedural)的
最近前向控制条件语句集合:指到达某条件语句s的所有条件语句栈中的某些条件语句t,这些条件语句t到该条件语句s之间不再包含其他前向控制条件语句
- 函数内的需满足:在同一个函数内,且当前条件语句的突变不会影响到该条件语句,这个可通过LLVM完成
- 函数外的需满足:在不同的函数内,t所在的函数ft在s执行时必须在程序栈上,执行s时的ft的最后一次call指令不能对t产生前向依赖
- 对其他非call跳转的函数外条件指令,只要其中一个分支走到了含非call跳转,就将跳转后的所有条件指令的前向指令都包含该指令
-
判断这些条件语句间的污点流的依赖关系,即判断对目标s的突变是否会对这些t的判断产生影响(排除掉没影响的),保留下真正有依赖关系的最近前向控制条件语句集合
-
解决这些依赖关系,考虑到执行效率,有如下三种方法,顺序去执行:
-
优先考虑可达性:仅改变非受t判断但受s判断的字节
-
优先考虑可满足性:
- 保留当前语句的前向条件的判断分支,突变s,判断对所有突变能否产生满足前向所有分支以及当前判断语句分支的输入
- 若不能,则回溯前向条件语句,对每次回溯的突变,避免产生对所有后向条件语句(包括s本身)的输入字节的突变
-
共同优化可及性和可满足性:联立这些条件语句的条件并使用梯度下降求解,如对之前的例子,有:
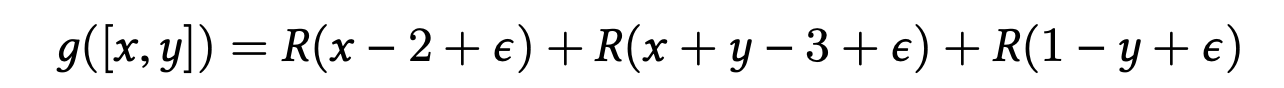
-
-
考虑到可能的非call指令导致的隐式跳转执行路径。作者首先使用前文描述的方法找到这写条件语句,并结合污点分析进行求解,在求解过程中遇到了污点爆炸的问题。作者还设计了线性的方法找到了真正产生依赖性质的条件语句集合的方法。而且表示由于Matryoshka仅对输入中很小一部分突变,因此这一步执行的非常少
Implementation
最终实现为一个基于Angora和LLVM PostDominatorTreeWrapper Pass两个工具的一个8672 行Rust、1262行c++的程序,称为Matryoshka
Evaluation
Intel Xeon Gold 5118+256G memory+64bit program+one core (Matryoshka也支持multicore)
each test 5 times, calc average
- LAVA-M数据集上的其他9个fuzzer比较
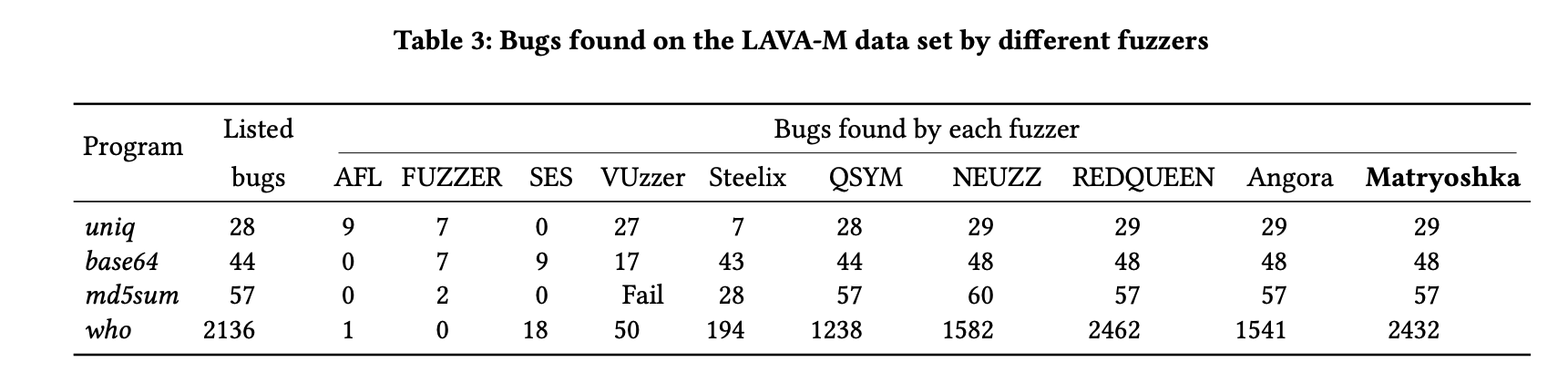
-
在13个开源程序上和其他几个fuzzer的比较
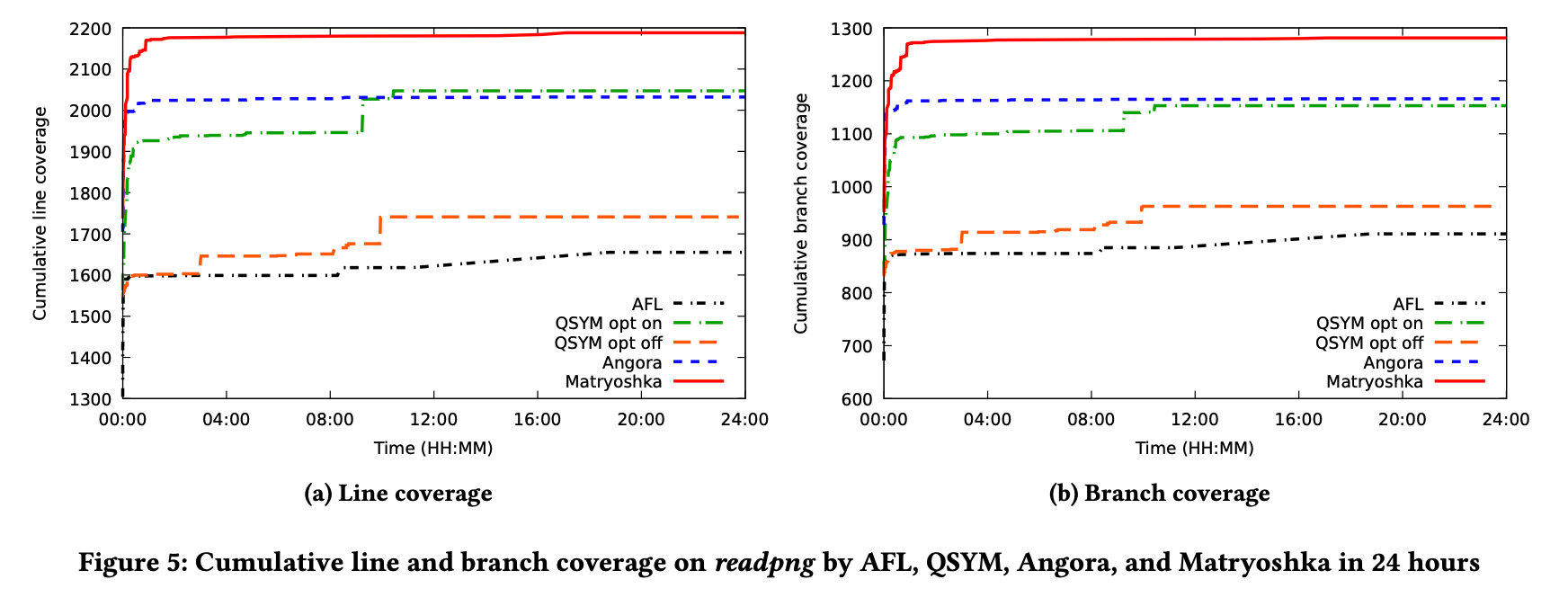
-
Matryoshka在所有程序上均胜过AFL,QSYM和Angora,但xmlwf,mutool和tiff2ps上Matryoshka的性能与Angora相似。 Matryoshka的优势在xmllint上最为突出,其中Matryoshka的行和分支覆盖率分别比覆盖率第二高的Angora分别提高了16.8%和21.8%。在readpng上的行和分支覆盖率
-
除了得到的crash,作者还将Matryoshka的输入种子合起来跑了ASAN,并使用
afl-cmin -C简化crash输入。最终在7个程序中找到41个独特错误(其他6个未找到),报告并得到了12个CVE
-
-
最后评估了Matryoshka的约束求解能力,主要是和基于的Angora比较,使用的种子输入是AFL产生的种子,显然Matryoshka能求解的范围是Angora的超集。而作者也发现优先考虑可满足性的策略是最为有效的
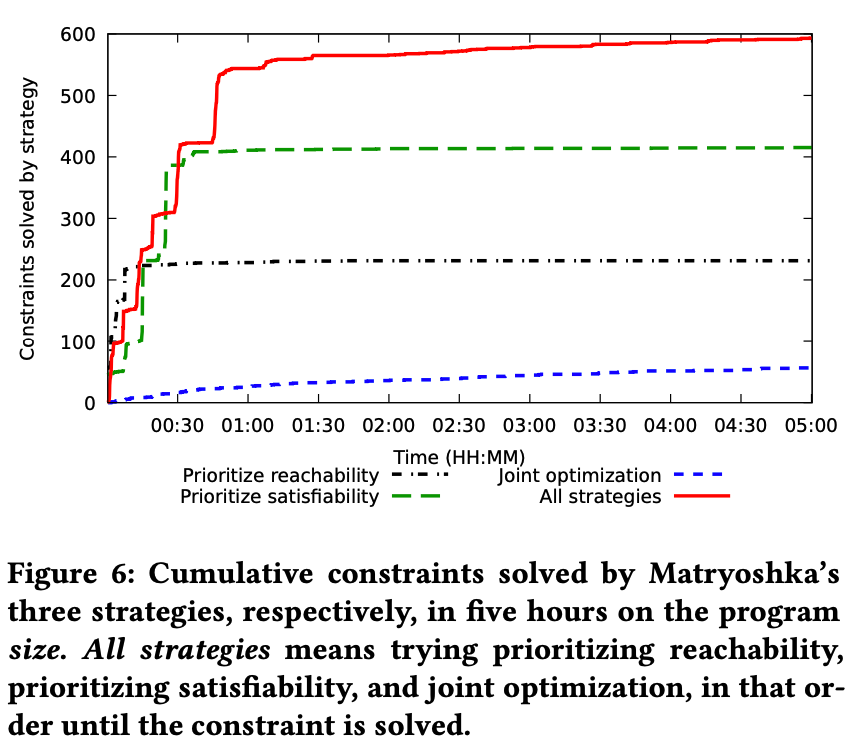
虽然联合求解最慢,但其可以在其他两种求解都基本达到完全时继续保持稳定速率求解。同时作者也分析了真正产生依赖的前向条件语句的比例在11个程序中少于5%,而所有13个程序中少于10%,因此这也是该工具效率能提升的一个很大原因。