由于其广泛应用和个人需要,在此对一些machine learning和deep learning的基础进行总结。
首先需要明确的是,人工智能(Artificial Intelligence)概念包括了机器学习(Machine Learning),而深度学习(Deep Learning)是机器学习中的一个更小但热度极高的一个方向,三者之间的关系可以总结为如下:
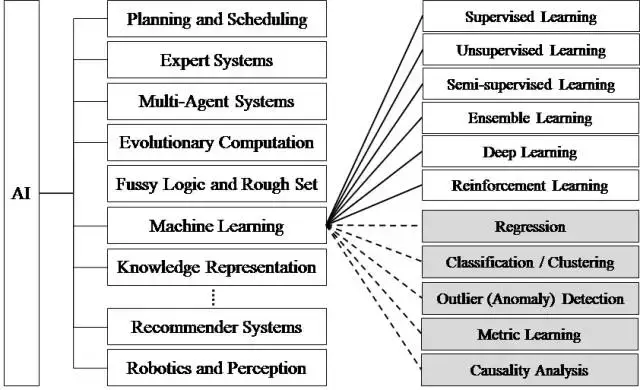
机器学习中包括一些传统的算法,如:决策树、聚类、贝叶斯分类、支持向量机等等。这些方法又可以分为监督学习(如分类问题)、无监督学习(如聚类问题)、半监督学习、集成学习、深度学习和强化学习。
而深度学习则是一种通过利用深度神经网络来进行有监督/无监督的机器学习的一种方法,由于计算机自身性能的提高,深度学习的训练时间和训练效果在变的越来越好。但深度学习自身既不是解决所有机器学习问题的最好选择:
- 深度学习模型需要大量的训练数据,才能展现出神奇的效果,但现实生活中往往会遇到小样本问题,此时深度学习方法无法入手,传统的机器学习方法就可以处理;
- 有些领域,采用传统的简单的机器学习方法,可以很好地解决了,没必要非得用复杂的深度学习方法;
- 深度学习的思想,来源于人脑的启发,但绝不是人脑的模拟,举个例子,给一个三四岁的小孩看一辆自行车之后,再见到哪怕外观完全不同的自行车,小孩也十有八九能做出那是一辆自行车的判断,也就是说,人类的学习过程往往不需要大规模的训练数据,而现在的深度学习方法显然不是对人脑的模拟。
也不是机器学习的终点(如下一代可能的迁移学习等技术),仅仅是当前一种效果较好,且有研究前景的一个机器学习热门方向而已。
特征的选取和处理
选取
对于数据预测,如股票预测,一般有如下的常用特征:
- open:开盘价
- high:当日最高
- low:当日最低
- close:收盘价
- vol:成交量(手)
- amount:成交额(元)
通过这些数据,我们可以通过一些计算得到二级特征:
- pre_close:前一交易日收盘价
- change:涨跌额
- pct_chg:未复权的涨跌额(未考虑由于送股、配股所发生的股票价格变动)
- 复权就是对股价和成交量进行权息修复,按照股票的实际涨跌绘制股价走势图,并把成交量调整为相同的股本口径。
除了上面的一些差分二级特征之外,还可以做一些变换、迁移二级特征:
- 前n天的一级、二级特征(lag_1/lag_2/lag_3/…)
- 去年同期的一级、二级特征
- vol/amount的log变换
处理
不同的特征往往有不同的计量方式,为了方便处理,通常会将其进行标准化,即:将数据按比例缩放,使之落入一个小的特定区间。
一种常用的标准化方式为z-score标准化(即零均值标准化),也就是对每个元素进行$\hat{x} = \frac{x-\mu}{\sigma}$的变换
Machine Learning
线性回归&多项式回归
概念略,线性回归中的超参数为选取用来拟合的窗口大小N,多项式回归种则还有多项式的阶数degree,在python的
from sklearn.linear_model import LinearRegression # 线性回归
from sklearn.preprocessing import PolynomialFeatures # 多项式回归
中可以实现对应的拟合方法
ARIMA时间序列预测模型
ARIMA模型的全称是差分整合移动平均自回归模型(Autoregressive Integrated Moving Average model)。
在给出ARIMA模型的定义之前,我们先来了解一下时间序列的平稳性。如果一个时间序列${x_t}$满足以下两个条件,则它是弱平稳的:
- 对于所有的时刻$t$,有期望$E[x_t]=\mu$,其中$\mu$是一个常数。
- 对于所有的时刻$t$和任意的间隔$k$,$x_t$和$x_{t-k}$的协方差$\sigma(x_t,x_{t-k})=\gamma_k$,其中$\gamma_k$与时间$t$无关,它仅仅依赖于间隔$k$。这称为方差平稳性。
有关协方差以及相关系数的概念可见:如何通俗易懂地解释「协方差」与「相关系数」的概念? - GRAYLAMB的回答 - 知乎。简单而言,协方差是一个可正可负的值,值越大,说明两个变量同向变化的程度越大,值越小,则两个变量反向变化的程度越大。$\sigma(X,Y)=Cov(X,Y)=E[(X-\mu_x)(Y-\mu_y)]$
我们可以通过时间序列平稳性校验(ADF检验)来判断时间序列是否是平稳的。在Python中,statsmodels和arch都提供了ADF检验:
from arch.unitroot import ADF
result = ADF(pdSeries) # or list
$x_t$和$x{t-k}$的相关系数$\gamma_k$称为$x_t$的间隔为$k$的自相关系数。在上述的弱平稳假设下,这个自相关系数和时间$t$无关,其仅仅依赖于间隔$k$。因而对序列的时间序列分析的核心即挖掘该时间序列中的自相关性。
而对于现实世界中的时间序列,我们需要将其分为可预测的部分和不可预测的部分。当原始时间序列为${x_t}$,我们预测的结果为${\hat{x}_t}$,则残差序列${e_t}$定义为${e_t}=x_t-\hat{x}_t$。如果我们的预测模型已经很好地捕捉了原始时间序列的自相关性,那么残差序列应该近似为白噪声。白噪声的定义为:如果一个时间序列满足均值为0,方差$\sigma^2$,且对于任意的$k\ge1$,自相关系数$\rho_k$均为0,则称该时间序列为一个离散的白噪声。对于预测白噪声,我们无能为力,也就是当我们预测结果的残差已经是白噪声了,相当于我们已经做到了极致。
而回到ARIMA的概念上来,提到ARIMA就需要先提到AR(Auto Regression,自回归)模型和MA(Moving Average,移动平均)模型,两者都是用来描述时间序列的:
-
自回归模型强调当前值和历史值之间的关系,用变量自身的历史事件数据对自身进行预测
对一般P阶(即选取历史上P个观测值)的自回归模型有:
$\hat{x}_t = c + \sum _{i=1}^p{\phi _i x _{t-i}} + \epsilon_t$
即:$x_t$可以表达为常数值、$t$时刻之前的$p$个观测值的线性组合以及一个$t$时刻的随机误差。
-
移动平均模型强调历史白噪声的线性组合,即可以认为当前的白噪声是历史q阶(即q个)白噪声的的线性组合(移动平均):
$\hat{x}_t = \mu + \sum _{i=1}^q{\theta_i \epsilon _{t-i}} + \epsilon_t$
即:$x_t$可以表达为平均值、$t$时刻之前的$q$个历史白噪声的线性组合以及一个$t$时刻的随机误差。
最终,将上述的两个模型结合,得到预测值同历史p个观测值,q个白噪音有关的$ARMA(p,q)$模型,即自回归滑动平均模型(Autoregressive Moving Average model):
$\hat{x}_t = c + \sum _{i=1}^p{\phi _i x _{t-i}} + \sum _{i=1}^q{\theta_i \epsilon _{t-i}} + \epsilon_t$
即:$x_t$可以表达为常数值、$t$时刻之前的$p$个观测值的线性组合、$t$时刻之前的$q$个历史白噪声的线性组合以及一个$t$时刻的随机误差之和。换句话说:
- AR是自回归,$p$为其中的自回归项数;
- MA为移动平均,$q$为移动平均项数
那么在此基础上添加一个参数$d$来得到最终的$ARIMA(p,d,q)$模型,$d$表示使得要预测的时间序列成为平稳序列所做的差分次数。
因此,要对时间序列使用ARIMA进行预测之前,首先得找到d,即找到序列的0, 1, 2…次差分,使得差分序列为一个时间平稳序列。
from arch.unitroot import ADF
close = train['close'] # 收盘价的0阶差分序列
print(ADF(close).summary())
change = train['change'] # 收盘价的0阶差分序列
print(ADF(change).summary())
当然,验证是否为时间平稳序列也是需要备择假设的,因此有把握度的要求,对于预测不准的情况也可以通过调整差分阶数、$p$、$q$的值等超参数来调整模型
# 使用cv值对超参数调参,主要是ARIMA中的阶数order
from statsmodels.api import tsa
order_list = [(3, 1, 0)] # 这里的超参数需要自己给出(属于是炼丹了)
for order in order_list:
model = tsa.arima.ARIMA(history, order=order)
# 拟合模型
# model_fit = model.fit(disp=False)
model_fit = model.fit()
# 预测一个数据点
output = model_fit.forecast()
...
需要注意的是,普通的差分可以看作是前后元素的差值,实际上还可以转化为计算对数增长率($\log \frac{x_{i}}{x_{i-1}}$)等形式
refer to this blog for more info
K近邻方法
K近邻方法(K-Nearest Neighbor, KNN):对给定的测试样本,基于某种距离度量找到训练集中和其最相近的k的训练样本,然后基于这k个“邻居”的信息来进行预测。这种常用在字符识别、 文本分类、 图像识别等领域。
常用的距离计算方式有曼哈顿距离($p=1$,线段距离)、欧氏距离($p=2$,平面距离)和切比雪夫距离($p=\infty$)。它们都属于闵可夫斯基距离(Minkowski distance)族
K近邻中的误差分为两种:
- 近似误差:对现有训练集的训练误差
- 估计误差:对测试集的测试误差
K值越大,意味选取近似的点越多,模型实际上越简单,近似误差越大,对输入的实例预测也越不准确(越容易对不同的输入产生一样的结果判断);K值越小,选取的点越少,模型越复杂,估计误差越大,对近邻的实例点越敏感(越容易受到噪声影响)
实际中K一般选较小的值,并交叉验证来选取最佳K值(也就是说K就是模型的超参数了),大致流程如下:
- 计算已知类别数据集中的点与当前点之间的距离
- 按距离递增次序排序
- 选取与当前点距离最小的k个点
- 统计前k个点所在的类别出现的频率
- 返回前k个点出现频率最高的类别作为当前点的预测分类
需要预测明天的对数收益率时,对筛选出的k个邻居的对数收益率的平均值作为我们的预测结果。
使用
from sklearn.neighbors import KNeighborsRegressor
来进行kNN预测,refer to link for more info
决策树
决策树本身的概念还是比较清晰:其通常包含一个根结点、若干内部节点和若干叶节点。叶节点对应了该决策树的决策结果,其他的每个节点则对应了一个属性的测试,每个节点包含的样本集合根据属性测试的结果被划分到子节点当中去。比如泰坦尼克号上,先根据乘客的性别、再逐个根据年龄、子女数量等属性划分优先撤离的人群的划分方法。
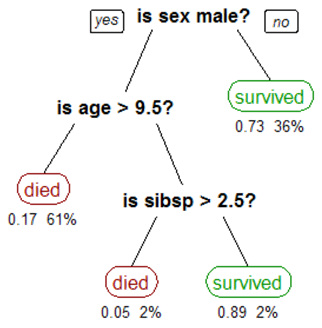
决策树的两大优点:
- 决策树模型可以读性好,具有描述性,有助于人工分析;
- 效率高,决策树只需要一次构建,反复使用,每一次预测的最大计算次数不超过决策树的深度。
构建决策树的方法如下:
- 开始,所有记录看作一个节点
- 遍历每个变量的每一种分割方式,找到最好的分割点
- 分割成两个节点$N_1$和$N_2$
- 对$N_1$和$N_2$分别继续执行2-3步,直到每个节点足够“纯”(即同一类的记录较多)为止
构架决策树时采用贪心算法,只考虑当前能产生最大纯度(对于当前节点区分出的每个分类计算一个纯度值,纯度之和减去该节点未分类时的纯度提升最大),的属性的分割值作为当前节点的分割点。
纯度值的计算有Gini不纯度、熵、错误率等计算方式,效果都差不多,一般使用熵公式即可: \(Entrophy = - \sum_{i=1}^n{P(i)*log_2(P(i))}\),其中$P(i)$为该节点在分割点分割下的每一类决策结果的记录数占节点记录数(如泰坦尼克克号上的游客是否可以优先撤离,可以/不可以两类)的比例。
上述这样一个递归的过程必须设置停止条件。一种最直观的方式就是当每个节点只包含一种类型的决策结果的记录为止,但这样容易导致树的节点过多,导致过拟合的问题;那么我们可以设置一个节点中的记录数阈值,当小于这个值时就不再分割,直接将$max(P(i))$对应的分类i作为该节点的分类。
但是,这仍然无法完全规避决策树的过度拟合问题,即使用该决策树对训练数据可以很准确,但在测试数据上却非常不准,过度拟合的原因可能有如下的几点:
- 噪音数据:训练数据中的噪音可能对分割点的判断有影响
- 训练集中缺少代表性数据:导致对某一类的数据无法很好的匹配,这一点可以通过观察混淆矩阵(Confusion Matrix)分析得出
- 多重比较(multiple comparision):指决策树上的大量分割点中,很容易出现个别的噪音分割点(即只是对当前的训练集的分割有效)。 举个例子,比如现在进行股票预测,分析者随机预测正确的概率为50%,每一个人预测10次,那么预测正确的次数在8次或8次以上的概率为$\frac{C_{10}^8 + C_{10}^9 + C_{10}^10}{2^{10}} \approx 5.47\%$。而如果现在拿50个分析者进行预测的结果,那么其中含有至少一个人得到8次或以上的人作为代表的概率则变成了$1-(1-5.47\%)^{50} \approx 93.99\%$,但选出来的这个代表实际上还是在进行随机预测,对之后的测试没有任何帮助。
对于如上的过度拟合问题,可以有如下的几种方式来缓解:
- 剪枝:减少节点数,剪枝对决策树的正确率影响非常大,主要又有两种裁剪策略:
- 前置裁剪 在构建决策树的过程中,提前停止。这通常导致更复杂的节点分割条件和更短小的决策树深度。结果就是往往决策树难以达到最优。大量的实践也证明这种策略难以得到较好的结果
- 后置裁剪 在构建完成后才进行裁剪,这又有两种方法:一是用子树中最主要的分类的叶节点来代替整个子树的判断;二是用一个子树来完全代替另一棵子树。后置裁剪就是比较浪费之前生成树的计算资源
- K-Fold Cross Validation:首先计算出整体的决策树T,叶节点个数记作N,设i属于$[1,N]$。对每个i,使用K-Fold Validataion方法计算决策树,并裁剪到i个节点,计算错误率,最后求出平均错误率。这样可以用具有最小错误率对应的i作为最终决策树的大小,对原始决策树进行裁剪,得到最优决策树。
- 随机森林:通过用训练数据随机的计算出许多决策树,形成一个森林,然后用这个森林对未知数据进行预测,选取投票最多的分类的方法。实践证明,此算法的错误率得到了进一步的降低。这种方法背后的原理可以用“三个臭皮匠,顶个诸葛亮”这句谚语来概括。一棵树预测正确的概率可能不高,但是集体预测正确的概率却很高。
集成学习模型
集成学习(Ensemble Learning)通过构建并结合多个学习器,将这些表现较弱的基础方法来合并起来完成学习任务:
- Boosting:先从初始训练集训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的样本在后续收到更多关注,并基于调整后的样本分布来训练下一个基学习器;如此重复进行直到选出T个基学习器。将这T个基学习器进行加权结合。XGBoost就是基于Boosting优化过的方法。
- Bagging:通过T轮有放回的m次随机采样,得到用来训练T个基学习器的T*m个样本数据(每个基学习器使用m个数据进行训练)。在每个基学习器开始对根结点开始分类前,随机森林算法还会从根节点的属性集合中随机选择其中k个子集属性来作为该基学习器的分类属性集合。随机森林算法(Random Forest, RF)是一种Bagging方法。
接下来介绍集成学习模型中的几个常用的方法:XGBoost(boosting)、随机森林(bagging)和GBDT(Gradient Boosting Decision Tree,梯度提升决策树)(boosting)
XGBoost
XGBoost全名为eXtreme Gradient Boosting,它是经过优化的分布式梯度提升库。
其他细节详见blog,反正我是一下没看懂=.=
XGBoostRegressor预测:
from xgboost import XGBRegressor
model = XGBRegressor(max_depth=..., n_estimators=...)
随机森林
在上一节中我们知道,由于单个决策树的表现往往受限,因此我们有的时候更经常使用基于决策树的集成方法。将每一棵决策树都当成一个分类器,那么对于一个输入样本,N棵树则会有N个分类结果。RF通过将所有的分类结果进行集成,将投票最多的结果指定为森林的最终输出,这就是属于Bagging方式的随机森林算法。
随机森林的生成流程如下:
- 如果训练集的总大小为M,选取$m<M$,对T棵树中的每棵树,随机且有放回的从训练集M中选取m个训练样本(这种采样方式也被称为bootstrap sample方法)作为该树的训练集(即整个森林要用到T*m个样本数据)
- 随机是为了排除非随机带来的树分类结果“过于一致”的问题
- 有放回是为了保证多个弱分类器(即每棵树)之间的属性共性
- 对每棵树,还要单独从原来的总特征维度K中选取k个特征来做特征子集(其中还需要$k«K$),每次每棵树的节点分裂是依据当前树的特征子集来进行分裂
- 每棵树都尽最大可能生长,且不剪枝(why?)
在这样的情况下,RF的超参数实际只有k值,k越大,森林中任意两棵树的相关性越大,森林中每棵树的分类能力越大,两个能力需要进行权衡
RandomForestRegressor预测:
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(max_depth=..., n_estimators=..., random_state=0)
关于RF的更多总结可移步blog
梯度提升决策树
GBDT和XGBoost一样,也是一种boosting算法
支持向量机SVM
了解SVM,首先要了解什么是支持向量。
首先一个概念则是线性可分:在二维空间上,两类点被一条直线完全分开被称为线性可分。将其扩展到多维空间,则能将其正确划分、且该超平面距离两个类别的最近的样本的距离最远的超平面$\omega^Tx+b=0$(矩阵形式)称为最佳超平面,即有:
- 两类样本分别分割在该超平面的两侧;
- 两侧距离超平面最近的样本点到超平面的距离最大。
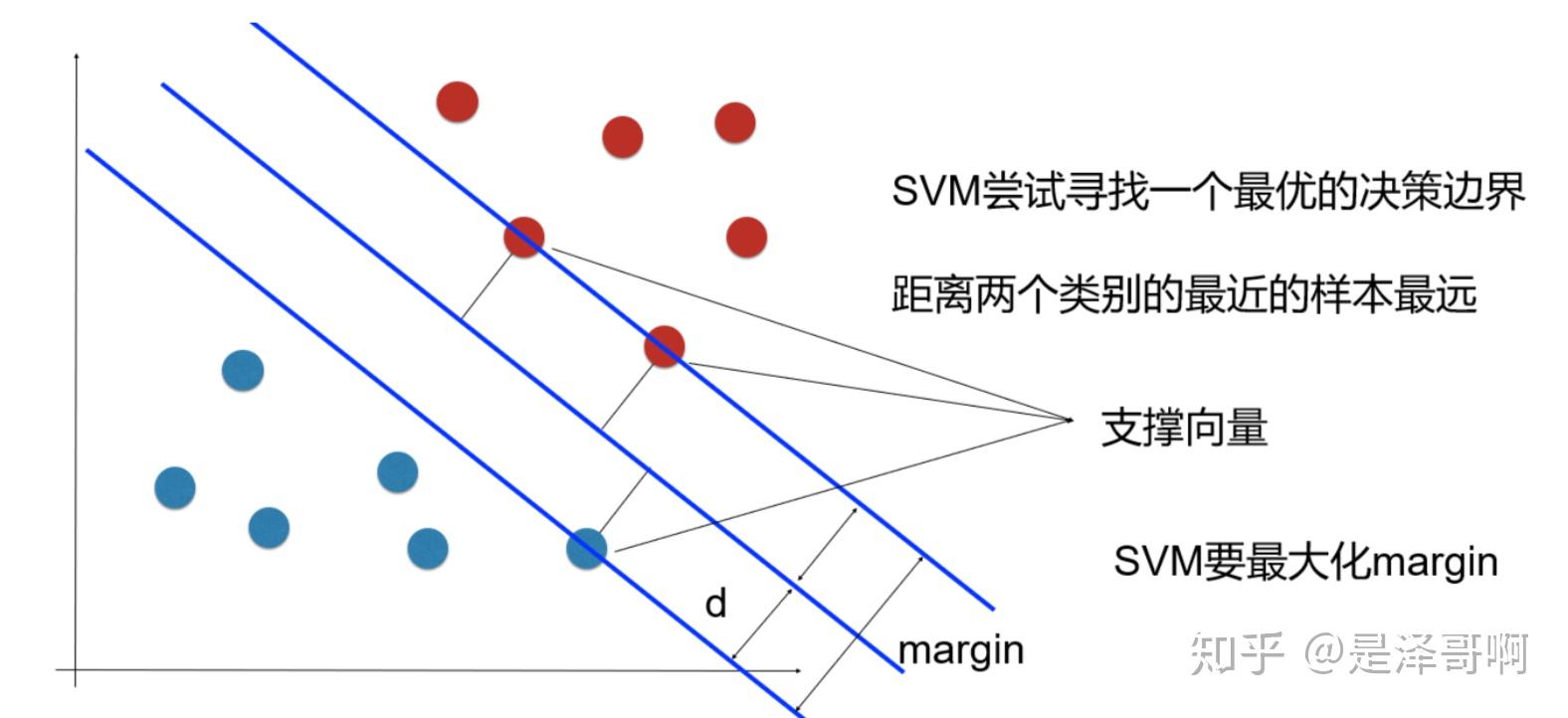
而支持向量,则是样本中距离超平面最近的若干个点。
SVM的最优化向量问题即找到如上所述的最大间隔超平面。任意的超平面都可以用如下的线性方程来描述:
\[\omega^Tx+b=0\]那么对二维空间,点$(x,y)$到直线$Ax+By+C=0$的距离公式是:
\[\frac{|Ax+By+C|}{\sqrt{A^2+B^2}}\]根据支持向量的定义我们知道,支持向量到超平面的距离为$d$,其他点到超平面的距离大于$d$。
对于SVM的实际求解流程中要应用到拉格朗日函数的构造、强对偶性的转化、序列最小优化算法求解(Sequential Minimal Optimization,SMO)等流程,具体可见这个知乎专栏
两类线性不可分问题
首先是非线性可分的问题:如果不存在这样的超平面可以将两类点刚好完全分开怎么办?
一种方式,如果可以通过给定一定的松弛程度(松弛变量$\xi_i, \xi_j$),可以得到软间隔
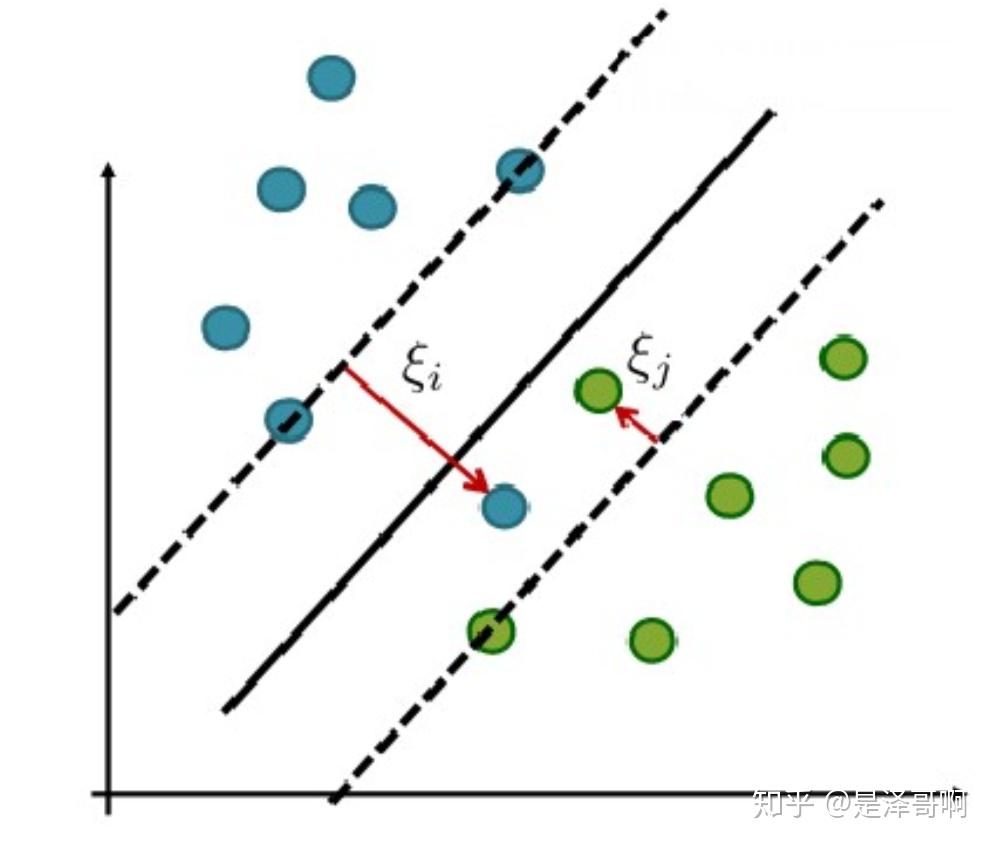
另一种方式,完全的线性不可分:
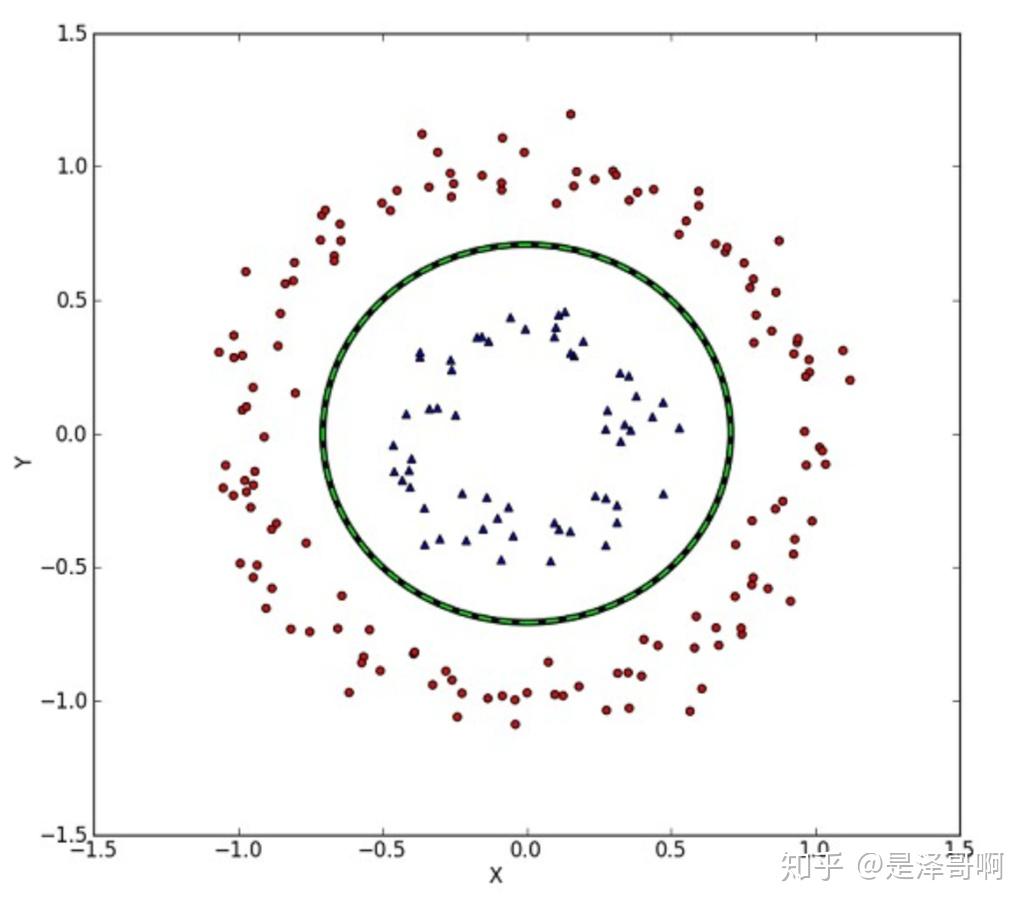
这种情况的解决方法就是:将二维线性不可分样本映射到高维空间中,让样本点在高维空间线性可分
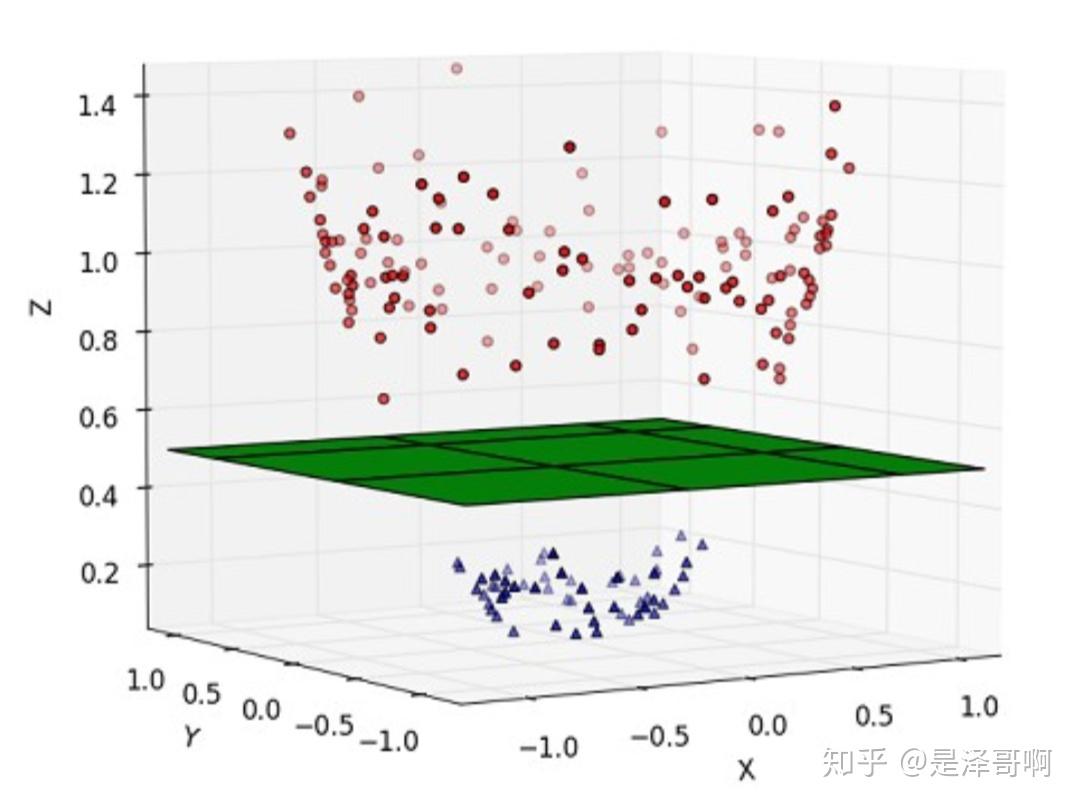
通常选用的映射方式需要满足:$x_i$与$x_j$在特征空间的内积等于它们在原始样本空间中通过函数$k(x,y)$计算的结果这一条件,这样可以减少计算量降低存储使用。
满足这种条件的映射函数则称为核函数,常用的有:
- 线性核函数$k(x_i, x_j)=x_i^Tx_j$
- 多项式核函数$k(x_i, x_j)=(x_i^Tx_j)^d$
- 高斯核函数$k(x_i, x_j)=exp(-\frac{|x_i-x_j|}{2\delta^2})$
SVM相关的几个术语:
- SVM:Support Vector Machine,支持向量
- SVC:Support Vector Classification,使用支持向量进行分类
- SVR:Support Vector Regression,使用支持向量进行回归分析
使用python-sklearn中的SVC来用SVM进行分类:
from sklearn.svm import SVC
model = SVC(c=..., random_state=0)
除上述的以外,还有:
svm.LinearSVCLinear Support Vector Classification.svm.LinearSVRLinear Support Vector Regression.svm.NuSVCNu-Support Vector Classification.svm.NuSVRNu Support Vector Regression.svm.OneClassSVMUnsupervised Outlier Detection.svm.SVCC-Support Vector Classification.(上述代码中使用的)svm.SVREpsilon-Support Vector Regression.
小结
上述的方法可以用来分类(如预测股票会涨还是会跌),也可以用来预测具体数值(如具体的涨跌幅度),取决于你用它是做分类classification还是回归regression分析
Deep Learning
深度学习(deep learning)是机器学习的分支,是一种以人工神经网络为架构,对数据进行表征学习的算法。其基本架构为人工神经网络,人工神经网络通过试图模拟人脑神经元的工作方式,通过数据来进行学习。
知乎专栏对MLP(ANN)、CNN和RNN做了比较全面的总结归纳。
多层感知器MLP
多层感知器(Multi-Layer Perception,MLP),属于全连接网络和深层神经网络的一种。
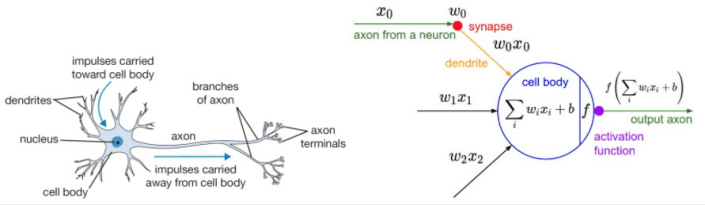
脑中的一个计算单元是一个简单的脑神经元。
脑神经元受到一个输入的信号,通过不同的突触,信号进入神经元,接着通过神经元内部的激活处理,最后沿着神经元的轴突产生一个输出信号,这个轴突通过下一个神经元的突触相连将输出信号传到下一个神经元。
在神经网络的计算模型中,输入信号就是输入数据,模型的参数就是突触,然后输入信号传入神经元就像是输入数据和模型参数进行线性组合,然后经过激活函数,最后传出模型。
模型参数通过学习可以控制输入数据传入神经元的强度,激活函数就是神经元内部的激活处理,最后将结果输出变成第二层网络的输入。
全连接网络(Fully Connected Network,FCN)指:前一层的神经元和下一层的所有神经元都进行连接。全连接网络中的每一层被称为全连接层(Fully Connected Layer,FCL)

深层神经网络(Deep Neural Network,DNN)通常用来强调含有多个隐含层的神经网络。
由上图可以看到,MLP的网络由3类Layer组成,分别为输入层,隐藏层和输出层,其中输入层的特征数目可以和输出层的结果数目不同。隐藏层的网络层数和每层中的神经元个数对于模型的影响非常大。同时,另一个起到影响作用的则是激活函数:
激活函数本质是用来做分类的一个函数:正样本就让激活函数激活变大,负样本就让激活函数激活变小。
常见的激活函数有Sigmoid、Tanh、ReLU、Leaky ReLU和Maxout等,一般常使用ReLU函数,其数学表达式为
\[f(x) = max(0, x)\]
神经元中的权重更新是在训练过程中通过反响传播来实现的。首先通过正向的计算得到结果,再根据真实的结果进行误差计算,并根据误差反向更新神经元当中的权重参数。
同时,对于MLP网络,并不是其中的每一个神经元都要用上,可以通过称为dropout的方式去掉一些神经元及其连接,使得网络更加稀疏,从而更好发挥剩余神经元的作用并减少过拟合的影响。


MLP通常作为神经网络的基础,在之后将要介绍的RNN、CNN以及一系列的衍生算法中的最后层基本都是classifier层(即全连接层),用来把之前通过CNN/RNN处理后获得的特征参数(features)进行最终的分类计算,获得预测每一个样本标签的概率。
MLP的反向传播算法——BP算法
BP算法(Back Proparation)是为了解决反向传播对权重进行参数学习的一种使用广泛的算法。其基本思想为:学习过程由信号的正向传播(求损失)和误差的反向传播(误差回传)两个过程组成,具体为:
- 正向传播过程中,根据输入的样本,给定的初始化权重值W和偏置项的值b,计算最终输出值及其和实际值之间的损失值(损失函数通常有交叉熵损失函数和平方误差损失函数等)。如果损失值不在给定的误差范围内则进行反向传播的更新,否则停止W和b的更新
- 反向传播过程中,将输出以某种形式通过隐层向输入层逐层反传,并将误差分摊给个层的所有单元,从而获得各层单元的误差信号,此误差信号即作为修正各单元权值的依据。
由于BP算法是通过传递误差值δ进行更新求解权重值W和偏置项的值b, 所以BP算法也常常被叫做δ算法.
关于BP算法的简单推导和简单示例可见该blog的2.2、2.3部分
卷积神经网络CNN
传统的机器学习算法需要人工定义features,然后用features喂进各种算法获得分类结果,这样的features选取需要建立在人的经验基础上,且很可能会遗漏一些特征信息。与传统的机器学习不同,CNN以及RNN都是可以及其自主学习features,自主优化每一层的weights来获取训练网络中最能代表特征的一组值。CNN多用于计算机视觉和图像处理的应用,是不考虑序列数据的一种网络模型,常用于图像方面的检测、分类、分割、增强等等。
refer to this CNN(卷积神经网络)是什么?有何入门简介或文章吗? - 机器之心的回答 - 知乎 answer for more info
循环神经网络RNN
除了用MLP这样的前向全连接网络之外,为了更好的模拟人脑行为,通常还会使用循环神经网络(Recurrent Neural Network,RNN),这种网络具有一定的短期记忆能力。这种设计使得其可以在考虑之前时刻输入的情况下有更好的表现,如:
- 视频的下一时刻内容预测
- 语音识别
- 相似音乐、商品推荐
- 文档前后文内容预测 等等
对于MLP,除了上述的输入、隐藏和输出层外,它还有一个延迟器来实现记录前一个输入的信息的功能:

对于其中的隐藏层,更加数学化的图示如下:
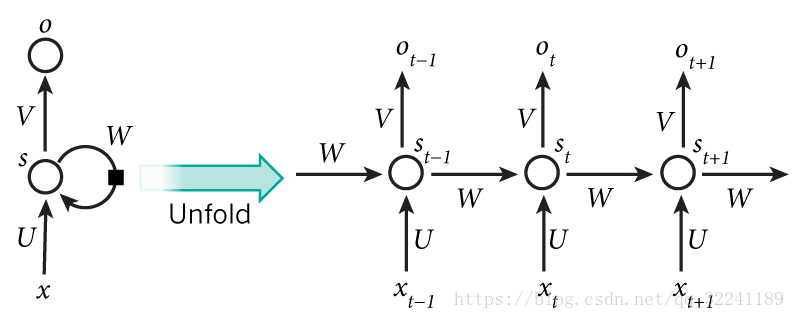
上述的$t-1$、$t$和$t+1$表示时间序列。$x$表示输入的样本。$s_t$表示样本在时间$t$处的记忆。则有:
\[\begin{cases} s_t = f(Ws_{t-1} + Ux_t) \\ o_t = g(Vs_t) \\ \end{cases}\]其中$W$表示历史记忆的权重,$U$表示当前时刻输入的样本权重,$V$表示输出的样本权重,$f$可以为常用的tanh、relu或sigmoid等函数,$g$可以为softmax等函数。
对于RNN的反向传播更新,除了应用BP算法外,还应该考虑到前若干个时刻的网络状态,这种改版的BP算法被称为BPTT(BP Through Time)算法
RNN算法对于处理时间序列的问题有着较好的效果,但是仍然还存在一些问题,其中较严重的问题便是容易出现梯度消失或者梯度爆炸的问题。为了解决这两个问题,出现了两种常见的改进算法:LSTM和GRU。
- 梯度消失(gradient vanishing):接近输出层的隐含层权值更新相对正常,但接近输入层的更新很慢,导致前面的层权几乎不变,仍接近于初始化的权值,导致原本多层的网络弱化为层数较少的网络
- 梯度爆炸(gradient exploding):与梯度消失相反,前面的层比后面的层变化更快
上述两个问题的出现都是因为网络太深导致网络权值更新不稳定造成的,本质上是因为梯度反向传播中的连乘效应。对于更普遍的梯度消失问题,可以考虑更换激活函数(如sigmoid->ReLU)或使用改进的RNN算法。
refer to blog for more info
长短期记忆网络LSTM
和RNN不同的是,RNN中通过线性求和的方式$h=Ws_{t-1} + Ux_t$来进行传递,而长短期记忆网络(Long Short Term Memory,LSTM)通过引入“门机制”来控制信息传递的路径。从概念上,不同的门会控制不同的信息进行遗忘、保存或输出的动作:
- 遗忘门:控制上一个时刻的内部状态需要忘记多少信息
- 输入门:控制当前时刻的候选状态需要保存多少信息
- 输出门:控制当前时刻的内部状态有多少信息需要对外输出
GRU算法是针对LSTM做的进一步改进,其将遗忘门和输入门合并成一个单一的更新门,同时合并了数据的单元状态和隐藏状态,使得模型结构相比于LSTM而言更加简单。
其他一些未提到但重要的术语:
- batch:梯度下降中,每次的参数更新有两种方式:
- 遍历所有的数据集去算loss function,再去算函数对各个参数的梯度,再更新梯度。这样要求每次都重新把数据集里的所有数据都跑一遍,对内存和计算量要求较大,这种方式称为batch gradient descent,批梯度下降
- 每看一个数据就算一次loss function,并求梯度且更新参数,这种方式称为随机梯度下降stochastic gradient descent,这种方法更新速度快但收敛不太好,还容易造成在最优点附近震荡 因此,为了综合以上两种方式,mini-batch gradient descent被提出,将数据集先进行分批后采用随机梯度下降,这个分批的大小便是当今训练中常见的batch_size参数
- iteration:一次iteration等于使用batch_size个数据进行一次训练,也就是每一次iteration都是对参数的一次更新,在iteration中包含了损失函数的计算和BP算法更新参数这两个过程。也就是有:$data\_size = batch\_zize * iteration\_time$
- epochs:周期,指向前和向后传播中,所有批次的单次训练迭代。也就是一个周期内,所有的数据将被过一遍
- sequence length:在LSTM中可能还会遇到一个seq_length的参数,有:$batch\_size = num\_steps * seq\_length$
工具安装
- TensorFlow:tensorflow本身是一个使用数据流图进行数值计算的开源软件代码库,数据流图中的节点代表数学运算,而图中的边则为在这些节点间传递的张量(即tensor),而这一特性能够很好的用在机器学习和深度学习网络的研究当中。其分为CPU版本(直接安装
pip install tensorflow)和使用GPU的版本(流程参考这篇文章)。除了python的接口外,tensorflow还有C++和Java的版本。 - Keras:是一个用python编写的一组更高层面的神经网络接口。直接
pip install keras即可,需要修改其配置文件来让其使用tensorflow作为后端